Neural Networks, CNNs, RNNs, Transformers, and Beyond
A (long) introduction to neural nets, and popular options of CNNs, RNNs, Transformers, and other modern machine learning models
Neural Networks: The Foundation
A neural network is a computational model inspired by the human brain. It consists of layers of interconnected neurons (or nodes), each performing a weighted summation followed by a non-linear activation function.
Mathematical Representation
Consider an input vector , weights , biases , and activation function . The output of a single layer is
Stacking these layers allows the network to learn hierarchical representations:
The figure below illustrates this "stacking" process:
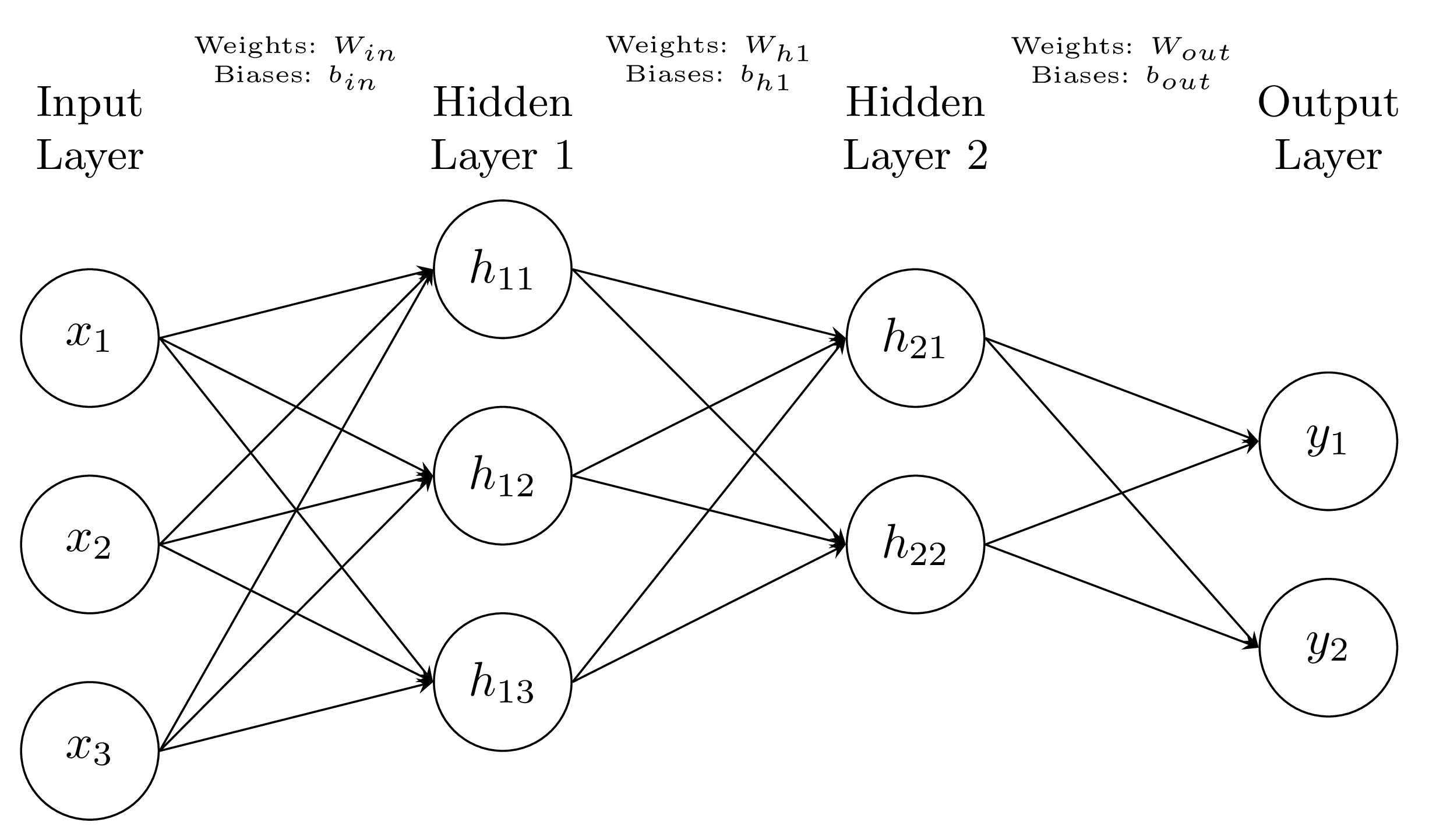
Training
It is now clear that training aims to obtain and . Define a loss function, , to be minimized by adjusting and , call them . The optimizer achieves this by repeatedly calculating the gradient of the loss function, , using backpropagation and updating the parameters via gradient descent. First, after a forward pass computes the network's output and its resulting error or loss, the backpropagation algorithm performs a backward pass. During this pass, it efficiently calculates the gradient of the loss function, , by applying the chain rule of calculus recursively from the final layer back to the first, determining how much each parameter contributed to the error. Finally, the gradient descent optimizer uses these calculated gradients to update all the network's parameters, , according to , slightly adjusting them to minimize future error. To create sparsity, add a regularization penalty like the norm, , to the loss function, which actively forces many parameter values to become zero.
Theoretical Foundations
The capacity of neural networks to approximate any continuous function on a compact domain is guaranteed by the universal approximation theorem(s), stating that a neural network with at least one hidden layer and a non-linear activation function can approximate any continuous function to an arbitrary degree of accuracy (Cybenko, 1989; Hornik et al., 1989). People later proved that a network with a fixed, minimal width can be a universal approximator, provided it can have arbitrary depth (Lu et al., 2017). These theorems are purely existential, offering no guarantees on the efficiency of learning algorithms or the number of neurons required to achieve a prescribed approximation error.
Surprisingly, the loss surface of a large multilayer network is not fraught with poor local minima but is instead dominated by numerous saddle points and local minima whose loss values are qualitatively close to the global minimum (Choromanska et al., 2015). Counterintuitively, overparameterization can improve generalization, a behavior reconciled by double descent, which subsumes the classical bias-variance trade‐off into a unified framework where increasing capacity beyond interpolation lowers test error due to implicit regularization by the optimization algorithm (Belkin et al., 2019).
Practical Implementation
Modern deep learning hinges on flexible frameworks that abstract computational graphs, automatic differentiation, and hardware acceleration to streamline prototyping and large‐scale training. One important problem is the vanishing or exploding gradients problem, which arises in deep networks because backpropagation repeatedly multiplies gradients through each layer, causing the update signal to either shrink exponentially toward zero (vanishing), which prevents early layers from learning, or grow uncontrollably large (exploding), which makes the training process unstable. Initialization schemes like He initialization align weight variances with layer activations to mitigate this.
Batch normalization stabilizes activation distributions and accelerates deep convolutional training by explicitly normalizing layer inputs via batch‐wise mean and variance (enabling higher learning rates and less sensitivity to initialization) (Ioffe & Szegedy, 2015). Recently, researchers found that the dynamic tanh approach, which replaces all normalization layers in Transformers with a single learnable element-wise , can further offer a practical, statistics-free alternative whenever batch or layer statistics are impractical or too costly (Zhu et al., 2025).
Adaptive optimizers such as Adam adjust per‐parameter learning rates based on estimates of first and second moments, offering robustness in sparse or noisy gradient scenarios and often outperforming vanilla SGD in practice (Kingma & Ba, 2014), overcoming the saddle point problem. Effective hyperparameter tuning—through systematic searches, Bayesian methods, or bandit algorithms—and rigorous experiment tracking (e.g., with TensorBoard or Weights & Biases) is critical for replicable state‐of‐the‐art results.
Empirical Understandings
Empirical scaling laws for language models demonstrate that cross-entropy loss follows power-law relationships with respect to model parameters, dataset size, and compute, allowing practitioners to predict performance gains and allocate resources optimally (Kaplan et al., 2020). The double descent phenomenon explains why enlarging model capacity can paradoxically reduce test error even after achieving zero training loss, unifying classical and modern generalization theories under one curve (Belkin et al., 2019). Moreover, the lottery ticket hypothesis reveals that within dense, randomly‐initialized networks lie sparse subnetworks (winning tickets) that, when trained in isolation, can match or exceed the accuracy of the full model, offering new directions for pruning and efficient inference (Frankle & Carbin, 2018).
Convolutional Neural Networks (CNNs)
CNNs are specialized for data with spatial structure, like images. Instead of fully connected layers, they use convolutional layers to extract local patterns, such as edges in images (corresponding to shapes in the image). Multiple layers are involved in this process (LeCun et al., 1998).

Mathematical Representation
A convolution operation involves a filter (or kernel) sliding over the input :
The output is called a feature map. The figure below illustrates this process:

The starting point of this illustration demonstrates that CNNs are naturally useful for images or videos — we can view each pixel as a single cell of the input above. Pooling layers (e.g., max pooling) then downsample these feature maps, reducing dimensionality:
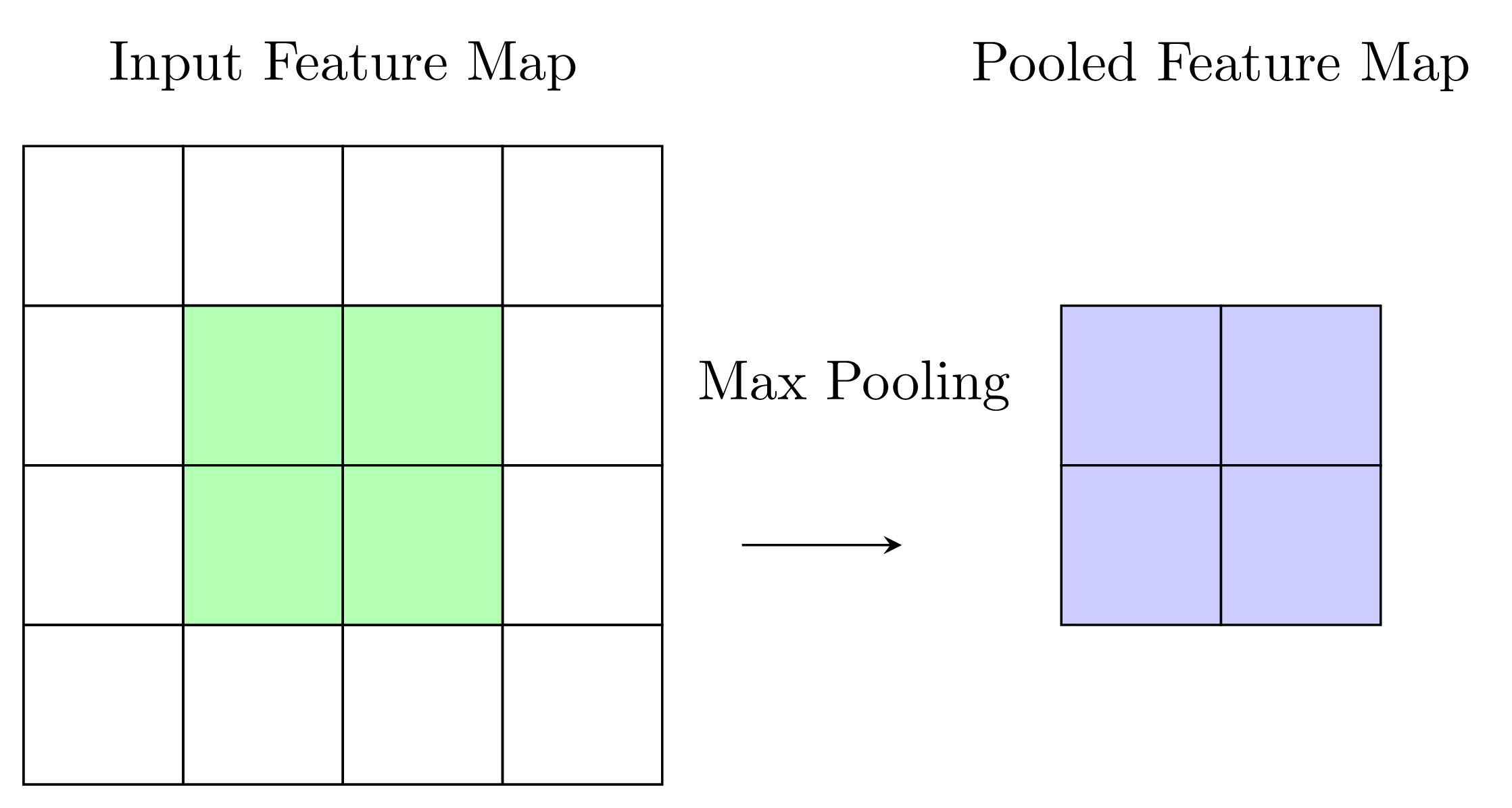
The flattening process converts the feature maps in to a 1-D vector (e.g., in ):
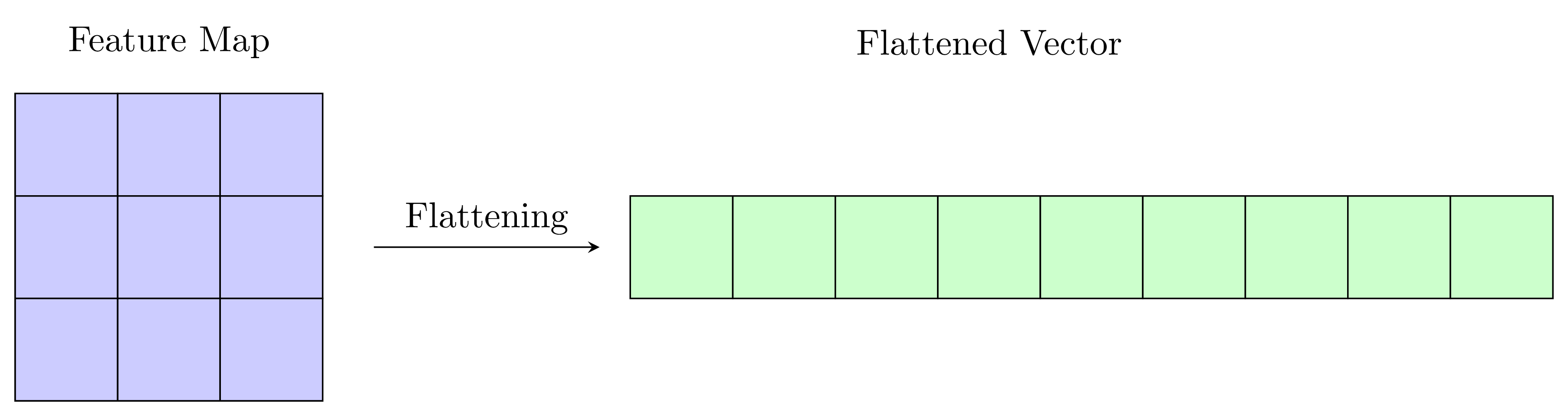
Lastly, a fully connected layer connects the vector to the output layer,
CNNs apply the same filter across the input and focus on local patches. Layers capture increasingly complex features (e.g., edges → textures → objects).
Foundations
The convolution operation embeds a translation equivariance prior by sharing the same kernel across spatial locations, drastically reducing the number of free parameters compared to fully connected layers and enabling the detection of local patterns regardless of their position in the image. Beyond parameter efficiency, the universal approximation properties of deep convolutional architectures stem from their ability to hierarchically compose simple linear filters and pointwise nonlinearities to approximate increasingly complex functions, a concept formalized in early work on multi-layer perceptrons and extended to convolutional settings (LeCun et al., 1998). The scattering transform framework interprets CNNs as cascades of wavelet convolutions and modulus operations, proving Lipschitz stability to deformations—a proxy for robustness to small geometric perturbations—while still capturing discriminative signal variations (i.e., higher-order interactions) (Mallat, 2012). Theoretical analyses have also shown a surprising result, where modern deep nets, including CNN, have enough capacity to memorize random labels (i.e., achieve zero training error on noise) with no explicit regularization (Zhang et al., 2016).
Empirical studies of feature transferability reveal that early convolutional layers learn general patterns such as edge and texture detectors, while deeper layers capture task-specific semantics; transferring features from mid-level layers provides the best balance between generality and specificity for new tasks (Yosinski et al., 2014).
Variants of CNNs
Early landmark models such as AlexNet (Krizhevsky et al., 2012) train on ImageNet (Deng et al., 2009) demonstrated that deep convolutional architectures trained on large-scale datasets with GPUs could achieve dramatic improvements in object recognition, introducing ReLU activations (), data augmentation techniques (in-memory reflections and intensity alternation), and dropout (temporarily randomly deactivating neurons) as a regularizer to mitigate co-adaptation of neurons. Subsequent architectures explored the impact of depth and filter granularity: VGGNets (Simonyan & Zisserman, 2014) showed that stacking small convolutions to reach depths of 16–19 layers yields improved representational power and transferability across tasks, while Inception modules factorized convolutions into multiple filter sizes to better utilize computational resources and capture multi-scale context (Szegedy et al., 2015). The introduction of residual connections overcame optimization difficulties in very deep models by reformulating each layer as a residual mapping, enabling stable training of networks exceeding 100 layers and pushing error rates below 4% on ImageNet (He et al., 2016). More recently, compound scaling methods systematically balance depth, width, and resolution by a single coefficient, resulting in EfficientNet families that deliver superior accuracy-efficiency trade-offs and generalize effectively across transfer-learning benchmarks (Tan & Le, 2019).
Fundamentals of Language Processing
Before introducing sequential models, let's first see how we can represent texts numerically, which is not as straightforward as image representation (pixel grids). Remember models understand numbers.
Before embedding, raw text is segmented into subword tokens via algorithms such as Byte-Pair Encoding, which greedily merges the most frequent character pairs to yield a fixed-size vocabulary that balances morphological expressiveness and open-vocabulary coverage (Sennrich et al., 2015).
Byte-Pair Encoding (BPE) Example
Initial State: Start with a corpus (e.g.,
low lower lowest) and break words into characters plus an end-of-word marker (l o w </w>). The initial vocabulary is just these characters.Greedy Merging: Iteratively find the most frequent adjacent pair and merge it into a new token.
- Step 1: The pair
l ois most frequent. Merge it to create the tokenlo. The vocabulary is now[l, o, w, ..., lo].- Step 2: The pair
lo wbecomes the most frequent. Merge it to createlow. The vocabulary is now[l, o, w, ..., lo, low].Result: This continues until a target vocabulary size is reached.
- Morphological Expressiveness: A known word like
lowestis tokenized into meaningful parts, like[low, est].- Open-Vocabulary Coverage: An unknown word like
slowercan still be represented by falling back to known subwords and characters, like[s, l, o, w, er].
Each token is then represented as a one-hot vector , where is the vocabulary size, and mapped into a dense embedding using an embedding matrix , capturing lexical semantics in a continuous space (Mikolov et al., 2013). Subword tokenization is the most efficient and manageable tokenization method thus far, as opposed to character and word tokenizations. Transformers inject positional information lost by parallel processing, a fixed sinusoidal encoding is added, where
yielding as the input to subsequent layers. The famous attention mechanism then comes into play (Vaswani et al., 2017).
For ideographic languages such as Chinese and Japanese, the default approach treats each character as a base token, but recent sub-character methods (Si et al., 2023) first transliterate characters into sequences of glyph strokes or phonetic radicals before applying BPE, allowing models to inject rich visual and pronunciation.
Recurrent Neural Networks (RNNs)
RNNs (Elman, 1990) excel at processing sequential data, such as time series or text. They maintain a memory of previous inputs via a hidden state, allowing them to model temporal dependencies.
Mathematical Representation
RNNs process data sequentially. At each time step , an input is provided. The sequence of inputs can be represented as , , up to , where is the total number of time steps. RNNs maintain a hidden state, , acting as the network's memory, updated at each time step based on the current input and the previous hidden state.
Given input , hidden state , and weights , , the hidden state is updated as
The output is computed as:
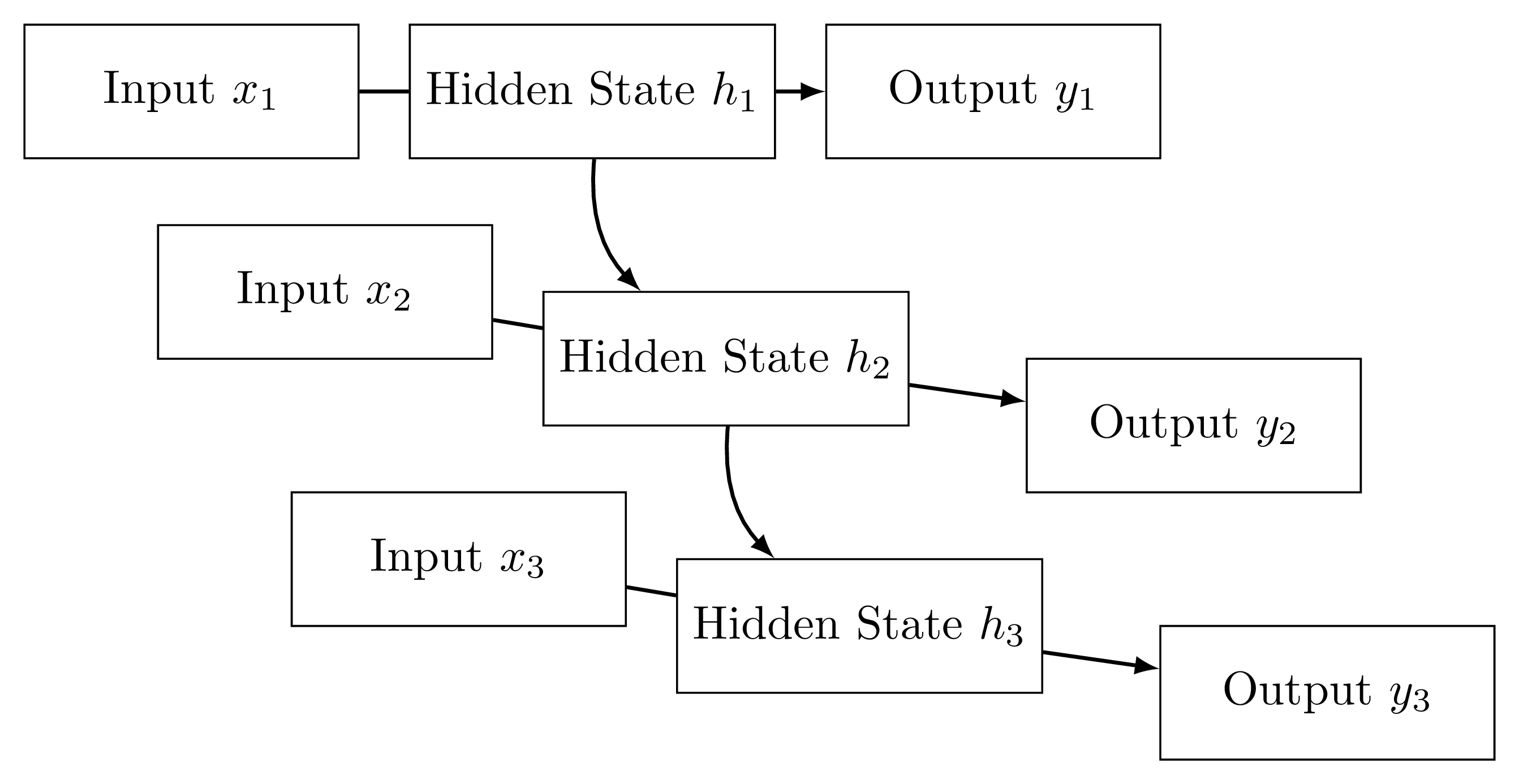
Limitations and Development
RNNs suffer inherently from gradients that either vanish or explode exponentially with depth in time when signals are propagated over many time steps, making naive RNNs impractical for long‐term dependencies (Hochreiter, 1998; Bengio et al., 1994). Long Short-Term Memory cells (Hochreiter & Schmidhuber, 1997) mitigate this by embedding gating units that learn to preserve information in a constant‐error carousel, thereby enabling the modeling of arbitrarily distant dependencies without gradient collapse. Subsequent work on Recurrent Highway Networks (Zilly et al., 2017) extended depth within each time step, applying gated residual connections to achieve deep transition functions that retain the LSTM’s long‐range memory while improving representational capacity. Alternative approaches constrain the recurrent weight matrix to be orthogonal or unitary, ensuring gradient norms remain constant and thus preserving signal propagation over arbitrary horizons without numerical instability (Arjovsky et al., 2016). Further, continuous‐time formulations like Neural ODEs reimagine recurrence as the discretization of a differential equation, offering a unified view of depth and time and opening the door to adaptive computation and memory allocation strategies (Chen et al., 2018).
Long Short-Term Memory (LSTMs)
LSTMs (Hochreiter & Schmidhuber, 1997) improve on standard RNNs by controlling the flow of information, using gates to selectively remember, forget, or output information, allowing the network to retain long-term dependencies. The graph below illustrates this sequential structure, which is structurally similar to RNNs:
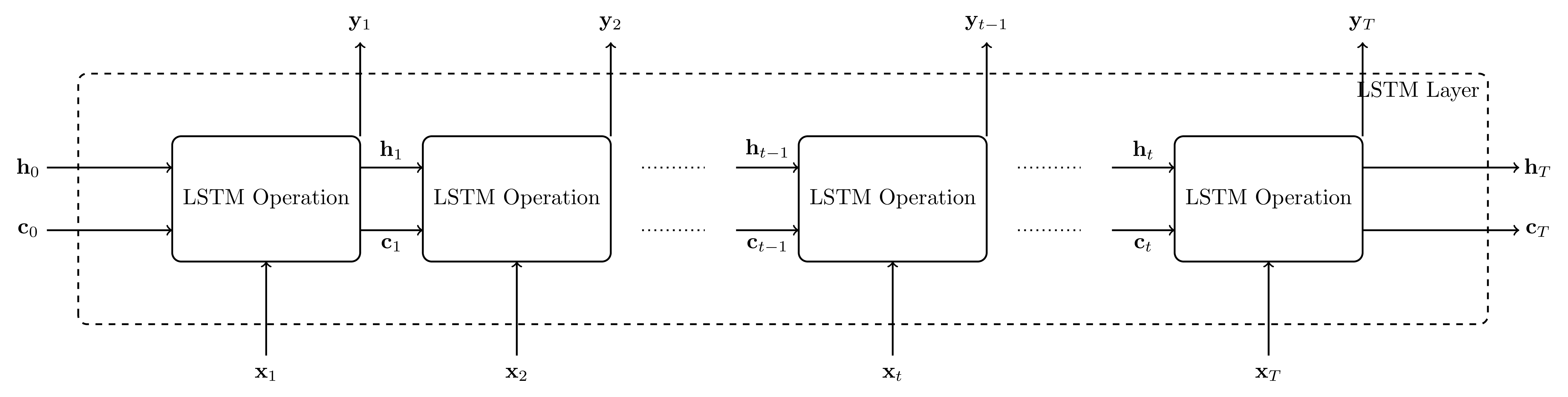
Mathematical Representation
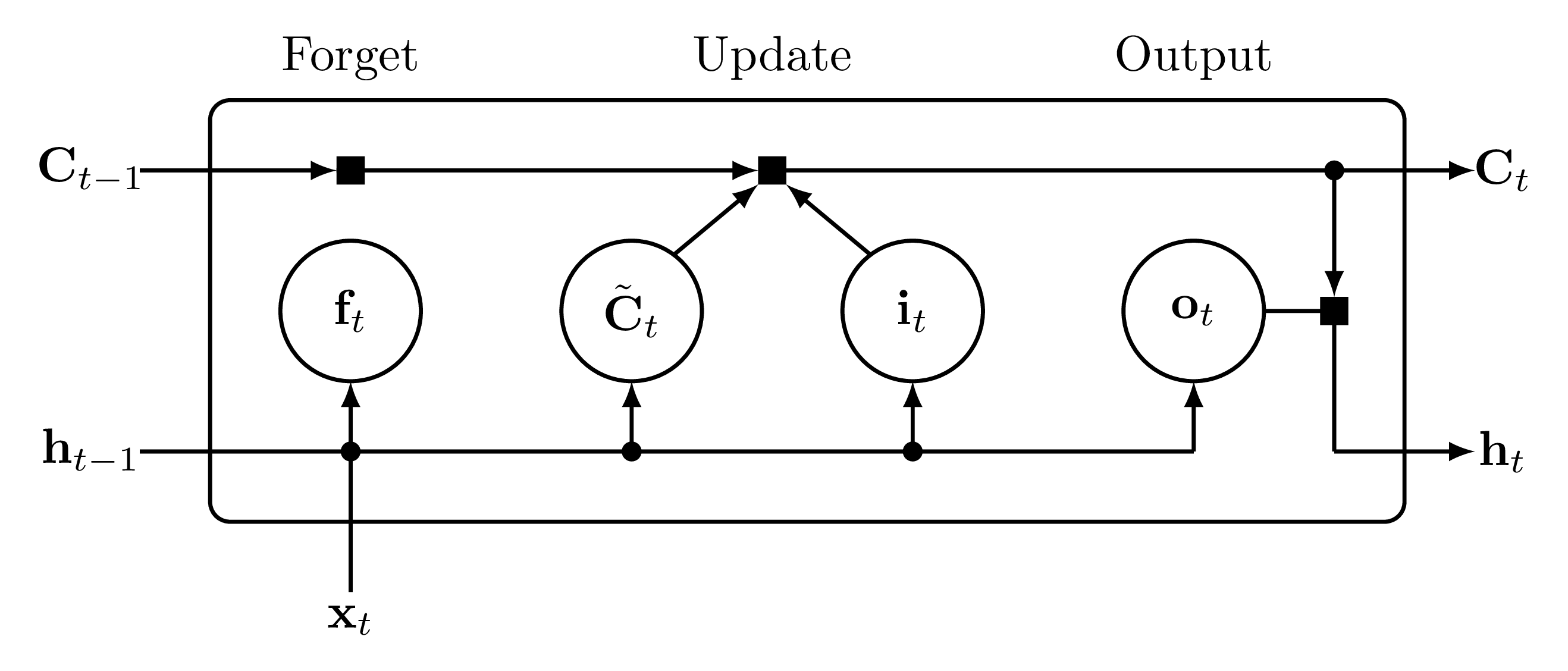
Here, is the sigmoid activation, is the hyperbolic tangent, and represents element-wise multiplication. At each time step , the LSTM maintains long-term memory called a cell state () and short-term memory called a hidden state (). They also introduce 3 types of gates:
-
Forget Gate (): Decides which information to discard from the cell state:
-
Input Gate (): Decides which new information to add to the cell state:
Candidate Cell State: The candidate cell state () is computed as:
-
Output Gate (): Decides the output based on the hidden state and cell state:
Updating the States
-
Cell State Update:
The forget gate decides what to discard, and the input gate decides what to add.
-
Hidden State Update:
The graph below illustrates this updating process:
Practical Implementation
Training recurrent models requires balancing sequence length, computational budget, and numerical stability; truncated backpropagation through time (TBPTT) (Williams & Zipser, 1989) limits gradient propagation to manageable windows while approximating full‐sequence gradients, and gradient clipping (Pascanu et al., 2013) prevents rare but disastrous exploding updates. Layer and weight regularization techniques—such as DropConnect in the AWD‐LSTM architecture (Merity et al., 2017) and variational dropout (Kingma et al., 2015)—act directly on recurrent weights and activations to reduce overfitting in language modeling tasks, allowing smaller datasets to yield robust sequence predictors. Modern deep learning frameworks provide native implementations of these gating and optimization schemes, and tools like mixed‐precision training and distributed sequence parallelism make it feasible to train very deep or very long‐sequence models on GPUs and TPUs with reproducible results.
Empirical Understandings
Empirical benchmarks on language modeling datasets reveal that carefully regularized LSTMs such as AWD‐LSTM achieve state‐of‐the‐art perplexities on Penn Treebank and WikiText‐2, demonstrating the continued relevance of gated recurrence for moderate‐scale tasks. However, scaling studies show that beyond a certain compute and data threshold, self‐attention architectures outperform traditional RNNs in both speed and quality (Kaplan et al., 2020), prompting hybrid approaches that inject attention mechanisms into LSTM backbones or employ Neural ODE layers for continuous modeling (Chen et al., 2018). Ablation experiments on gating variants and transition depths indicate that deeper recurrent transitions and highway connections yield diminishing returns beyond a handful of layers per step, suggesting that future gains will depend on novel memory‐access patterns or adaptive computation time mechanisms. As attention-first models (introduced next section) continue to dominate, the most promising directions revive recurrence through continuous dynamics, orthogonal memory networks, and differentiable neural computers that combine the best of gating, memory, and attention in a unified framework.
Transformers
In the transformer (Vaswani et al., 2017), we represent an input sequence of tokens by their embeddings and compute three projections—queries , keys , and values —each in . Self‐attention is then given by
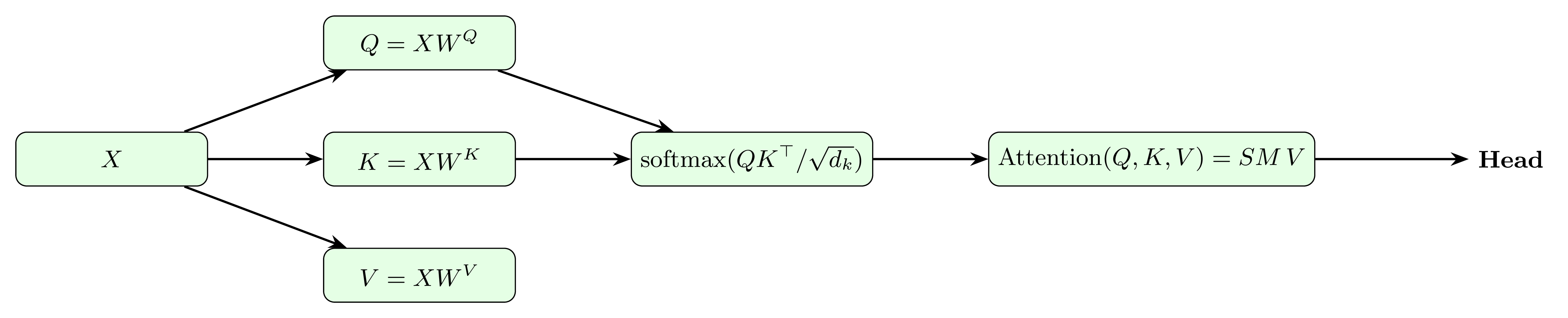
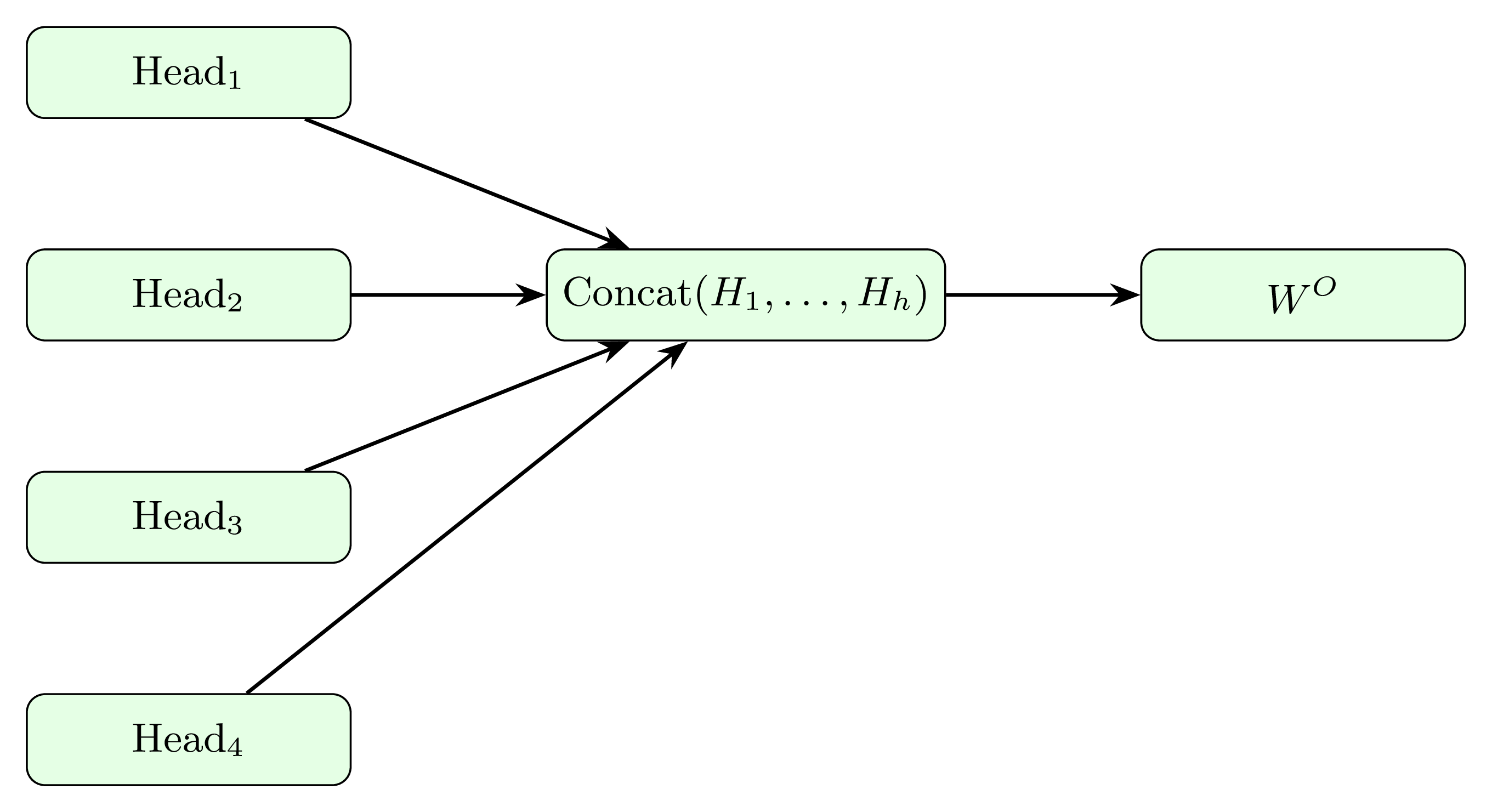
Multi‐head attention runs this in parallel for heads and concatenates the results:
Each transformer layer applies a residual connection plus layer normalization, , followed by a position‐wise feed-forward network
and another residual‐norm step . Stacking such layers yields the final contextual representations used for downstream prediction.

Different Types of Transformers
Beyond the canonical vanilla Transformer, nearly every variant introduces one or more mathematical tweaks to attention, embeddings, or the layer‐stacking strategy. A common class of modifications concerns positional information, via learned absolute embeddings (BERT, GPT-2/3, RoBERTa), relative position biases (Transformer-XL, T5, DeBERTa), or rotary position embeddings (RoFormer, GPT-NeoX). In the original model, we add fixed sinusoidal encodings so that the input to layer 1 is . Later work replaces these with learned embeddings , relative position biases , so that attention becomes
where depends only on , or even rotary embeddings that apply a learnable rotation to each pair of dimensions in and before dot‐product. Such tweaks allow the model to better generalize to sequences longer than it saw in training, or to bias attention toward nearby tokens without explicit masking.
Another rich vein of innovation is efficient or specialized attention. For truly long sequences, full attention is quadratic in cost; sparse‐attention variants insert a structured mask so
where for disallowed pairs (e.g. sliding windows in Longformer or random/global tokens in BigBird). Low‐rank or kernelized methods approximate
via feature maps , yielding linear time (Performer). Other approaches project keys and values to a lower dimension: Linformer posits learnable , so that , , reducing attention to . Finally, mixtures‐of‐experts (Switch Transformers) replace each feed‐forward block with a routing mechanism that selects among experts, so
trading depth for conditional computation. Other architectures include GShard and GLaM.
Together, these mathematical tweaks—positional biases, sparse or low‐rank attention, kernel approximations, adaptive‐depth recurrence (Universal Transformer), and conditional computation—form a rich taxonomy under the transformer umbrella, each tailored to specific tasks, modalities, or resource constraints.
Theoretical Understandings
A Transformer layer computes scaled dot-product attention, where queries, keys, and values are linear projections of the same input; the resulting attention matrix is then normalized by to maintain gradient stability, and softmaxed to produce a distribution over positions (Vaswani et al., 2017). Multi-head attention extends this by learning multiple sets of projections, allowing the model to jointly attend to information from different representation subspaces at distinct positions, which empirically enhances expressivity and enables parallel processing of dependencies. Formal analysis reveals that self-attention matrices can approximate arbitrary sparse matrices—thus capturing selective interactions among tokens—provided sufficient hidden dimensionality, granting Transformers a universal approximation property for sequence-to-sequence functions. Positional encodings—either fixed sinusoidal functions or learned embeddings—inject order information lost by the permutation-invariant attention mechanism, allowing the network to distinguish between positions in a sequence while preserving the ability to generalize to longer sequences than seen during training. Recent theoretical work also explores linearized and sparse variants that reduce the quadratic complexity of full attention to linear or near-linear bounds, trading off exactness for scalability without sacrificing universal expressivity in the limit.
Practical Implementation
Effective Transformer training hinges on stabilized optimization. The AdamW optimizer decouples weight decay from gradient updates, mitigating the tendency of adaptive methods to over-regularize while preserving the fast convergence of Adam; coupled with a linear warmup schedule for the learning rate (often over the first 10% of training steps), it prevents instability caused by large initial updates. Gradient clipping is commonly employed to bound the norm of gradients, curtailing occasional spikes during backpropagation that could derail learning, especially in deep or high-capacity models. Frameworks such as the Hugging Face Transformers library provide modular building blocks—pretrained checkpoints, tokenizer classes, and optimized training loops—enabling researchers and practitioners to experiment with architectures like BERT, GPT, T5, and beyond using both PyTorch and TensorFlow backends with minimal boilerplate. Mixed-precision training (via NVIDIA’s Apex or native AMP) significantly reduces memory usage and increases throughput by storing activations and performing many computations in a 16-bit floating-point format; to maintain numerical stability, a 32-bit master copy of the weights is used for accumulating gradients, a process that necessitates dynamic loss scaling to prevent underflow of small gradient values. Recent adapter-based fine-tuning methods such as LoRA inject low-rank parameter updates into attention layers, slashing the number of trainable parameters for efficient domain adaptation without full-model retraining. Additionally, in-context learning allows large-scale Transformers to perform novel tasks by conditioning solely on a handful of demonstration examples in the input prompt, without any gradient updates to model.
Empirical Understandings
Empirical scaling laws for Transformers reveal that cross-entropy loss on language tasks follows a power-law decay as a function of model parameters, dataset size, and compute budget, enabling precise forecasts of performance improvements for scale investments (Kaplan et al., 2020). At extreme scales, emergent capabilities—such as few-shot in-context learning, chain-of-thought reasoning, and compositional generalization—materialize abruptly and unpredictably, indicating qualitative shifts in model behavior that defy simple extrapolation from smaller models (Wei et al., 2022). Benchmarks comparing encoder-only models (e.g., BERT), decoder-only models (e.g., GPT), and encoder-decoder models (e.g., T5) demonstrate trade-offs between understanding and generation: encoder-only excels on classification and extraction tasks, decoder-only leads on open-ended generation, and encoder-decoder offers strong performance in sequence transduction. Fine-tuning studies show that the highest layers capture task-specific features while mid-layers encode transferable linguistic abstractions, guiding strategies for parameter freezing or adapter insertion during domain adaptation. As attention-driven models continue to dominate, the frontier now lies in integrating external memory, adaptive computation time, and hybrid architectures that marry recurrence, attention, and continuous-depth dynamics to push the envelope of sequence modeling further.
Generative Models
Generative modeling is one very important field in current applications and it encompasses a variety of approaches that trade off sample quality, training stability, and computational cost.
Generative Adversarial Networks (GANs)
A GAN consists of two neural networks— generates candidate samples from random noise, and discriminates between real and generated data—trained in a minimax game that converges when reproduces the true data distribution and cannot distinguish samples (Goodfellow et al., 2014). The core objective
encodes a zero-sum game where seeks to maximize its classification accuracy while seeks to fool . Intuitively, this adversarial setup avoids explicitly defining a distance metric between distributions; instead, implicitly shapes ’s loss.
GANs are favored when high-resolution, perceptually realistic samples are required—image synthesis, style transfer (e.g., pix2pix), and data augmentation in medical imaging. However, training dynamics can oscillate or diverge, and GANs commonly suffer from mode collapse, where outputs limited variations, undermining data diversity. Techniques like Wasserstein GANs (Arjovsky et al., 2017), two-time-scale updates, and minibatch discrimination partially mitigate these failures, but stable convergence remains a challenge.
Variational Autoencoders (VAEs)
VAEs frame generative modeling as approximate inference in a probabilistic graphical model (Kingma & Welling, 2013). An encoder network parameterizes a variational posterior over latent , and a decoder network defines . Training maximizes the evidence lower bound,
balancing reconstruction fidelity against a Kullback–Leibler penalty that regularizes toward the prior . The reparameterization trick—expressing with —enables gradient descent.
VAEs excel in learning smooth, disentangled latent spaces for downstream tasks like interpolation, anomaly detection, and semi-supervised classification. They train reliably via maximum likelihood principles but often yield blurry outputs due to pixel-wise losses and can collapse the posterior to the prior (posterior collapse), losing latent expressivity. Intuitively, one can imagine this as a librarian giving up on complex filing systems and simply dumping every single book, regardless of what it is, directly into the central pile. Remedies include KL annealing, -VAEs, and alternative divergences.
Diffusion Models
Diffusion models cast generation as the learned reversal of a gradual, data-corrupting noising process (Sohl-Dickstein et al., 2015; Ho et al., 2020). This forward process is defined as a Markov chain that systematically adds Gaussian noise to the data over successive steps:
To generate new samples, a neural network—often a U-Net—is trained to learn the reverse "denoising" process, . The network is optimized by minimizing a variational upper bound on the negative log-likelihood, which trains it to reconstruct the data by incrementally removing the noise step by step.
By sidestepping adversarial objectives, diffusion models offer stable training and have achieved superior fidelity in image and audio synthesis—powering DALL-E 2 and Stable Diffusion—while supporting inpainting, super-resolution, and conditioned generation. Their main limitation is inference cost: thousands of sequential denoising steps lead to slow sampling and high compute demands, motivating research on accelerated samplers and trading off steps for quality.
State Space Models (SSMs)
State space models formalize sequential data by positing an unobserved (latent) state that evolves linearly under additive Gaussian noise and generates observations through another linear mapping. In the canonical form,
where denotes known inputs, and are covariance matrices governing process and measurement noise (Kalman, 1960).
Intuitively, the latent state captures the system’s memory and structure, while Bayesian filtering algorithms (e.g., the Kalman filter) recursively update the posterior as new data arrive. The Kalman filter computes the minimum-variance estimate of the latent state via a predict–update cycle:
It yields the optimal minimum mean-square error estimate by minimizing under Gaussian noise assumptions. When exact Gaussian updates become intractable—due to nonlinearity or high dimensionality—sequential Monte Carlo and MCMC methods provide flexible approximate inference.
These models are prized for handling noisy, partially observed time series: they naturally accommodate measurement error, cope with missing data, and decompose signals into interpretable components such as trend and seasonality. The linear Gaussian assumption, however, can fail when dynamics are strongly nonlinear or noise is non-Gaussian. The extended Kalman filter may diverge under severe nonlinearity, and even unscented variants can underperform if noise covariances are misspecified. More critically, simple SSMs can exhibit biased or imprecise parameter estimates when measurement error dominates true signal variance.
In practice, state space models underpin econometric forecasting and structural time series analysis, speech recognition via continuous-emission HMMs, robotic localization and SLAM through probabilistic state estimation, and modern deep latent-variable learning such as deep Kalman filters for counterfactual inference in health care and vision (Krishnan et al., 2015). Recent advances in Gaussian process state-space models and fully variational inference further extend classical SSMs to nonparametric, high-dimensional settings.
Graph Neural Networks (GNNs)
GNNs generalize deep neural networks to graph-structured data by iteratively aggregating information from each node’s local neighbourhood. Formally, a -th layer representation of node is given by
where and denotes edge features. This message-passing paradigm casts learning as finding a fixed point of a contraction mapping over node states, ensuring convergence under mild conditions (Scarselli et al., 2009). A widely used special case is the graph convolutional network, which approximates localized spectral graph convolutions via
with and the augmented degree matrix, yielding scalable filters on irregular domains (Kipf & Welling, 2017).
Intuitively, GNNs capture both attribute and structural information by smoothing and propagating features along edges, effectively exploiting the homophily principle prevalent in many real-world networks; empirical evidence shows such pooling enhances node and graph embeddings for downstream tasks. However, the representational capacity of standard GNNs aligns with the Weisfeiler-Lehman test: without injective aggregation functions, message-passing GNNs cannot distinguish certain non-isomorphic graphs, motivating more expressive variants.
GNNs have become a de facto choice for node classification, link prediction, and graph-level tasks across domains such as social recommendation, molecular chemistry, and traffic forecasting, thanks to their relational inductive biases and ability to handle non-Euclidean data. Nonetheless, they can suffer from over-smoothing: as layers deepen, node embeddings converge to similar vectors, degrading discrimination capacity; this phenomenon has been formalized and mitigated through techniques such as residual connections, normalization, and graph rewiring, with recent work proving residual links provably mitigate oversmoothing rates.
Practically, GNNs underpin breakthroughs such as AlphaFold’s Evoformer for protein folding, spatio-temporal traffic forecasting, recommender systems exploiting user-item graphs, and combinatorial solvers leveraging relational inductive biases, showcasing their versatility in modeling heterogeneous and dynamic graph data.
Deep Reinforcement Learning
Deep reinforcement learning formalizes sequential decision‐making as a Markov decision process, defined by a state set , action set , transition dynamics , reward function , and discount factor , with the goal of finding a policy that maximizes the expected cumulative discounted return . Exact solutions rely on the Bellman equations, for example
but tabular methods scale poorly when or is large (Sutton & Barto, 2018).
Deep neural networks serve as function approximators for value functions or policies, trained via stochastic gradient descent on losses such as the temporal‐difference error
as introduced in the Deep Q‐Network (DQN) algorithm. Actor‐critic methods generalize this approach to continuous action spaces by maintaining both a critic and an actor , updating the latter via the deterministic policy gradient , as in Deep Deterministic Policy Gradient (Lillicrap et al., 2016).
The core intuition of deep reinforcement learning is that deep networks can extract abstract features from raw sensory inputs, enabling end‐to‐end learning of complex behaviors without manual feature engineering. This allows agents to directly map high‐dimensional observations to actions, as demonstrated by DQN’s human‐level performance on a suite of Atari games, where the agent learned directly from pixel inputs and sparse reward signals.
Despite these advances, deep RL often fails due to extreme sample inefficiency, requiring millions of interactions to converge—an untenable cost in real‐world settings where data collection is slow or expensive. Training can also be unstable because of nonstationary targets, correlated samples, and hyperparameter sensitivity, which can lead to catastrophic forgetting or divergence unless techniques like experience replay buffers and target networks are employed carefully.
Deep RL excels in domains with well‐defined simulators or abundant data: game playing (e.g., Atari via DQN and Go via AlphaGo and AlphaGo Zero) (Silver et al., 2016), robotics for locomotion and manipulation under physics‐based simulation and real‐world trials as surveyed in recent robotics deployments, autonomous driving and resource allocation in networking, finance for portfolio optimization and algorithmic trading, and healthcare for treatment planning and personalized intervention strategies.
Ethical and Societal Implications
Algorithmic systems can perpetuate and even amplify biases present in training data, leading to unfair outcomes across demographic groups as studied extensively; these biases may arise both from historical inequities encoded in data and from algorithmic design choices that inadvertently disadvantage protected groups. Efforts to protect individual privacy via formal techniques such as differential privacy provide mathematical guarantees against reidentification but introduce trade-offs with utility and require meticulous implementation—floating-point pitfalls and parameter tuning can silently undermine privacy guarantees (Dwork et al., 2014). AI technologies also enable the rapid generation and dissemination of misinformation, and the malicious use of AI for disinformation campaigns, cyber-threat development, and political manipulation presents urgent challenges. The substantial computational resources demanded by training and deploying modern models entail significant environmental footprints, and the energy and carbon costs of deep learning and recommending targeted policy interventions—concerns reinforced by subsequent studies on sustainable NLP practices (Strubell et al., 2020). Accountability and transparency in AI systems remain paramount, as interpretability frameworks strive to render model decisions understandable, auditable, and contestable; however, the lack of consensus on definitions and evaluation metrics for interpretability underscores the need for a rigorous science of explainability (Doshi-Velez & Kim, 2017).
References
Arjovsky, M., Shah, A., & Bengio, Y. (2016). Unitary evolution recurrent neural networks. International Conference on Machine Learning, 1120–1128.
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. International Conference on Machine Learning, 214–223.
Belkin, M., Hsu, D., Ma, S., & Mandal, S. (2019). Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proceedings of the National Academy of Sciences, 116(32), 15849–15854.
Bengio, Y., Simard, P., & Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), 157–166.
Chen, R. T., Rubanova, Y., Bettencourt, J., & Duvenaud, D. K. (2018). Neural ordinary differential equations. Advances in Neural Information Processing Systems, 31.
Choromanska, A., Henaff, M., Mathieu, M., Arous, G. B., & LeCun, Y. (2015). The loss surfaces of multilayer networks. Artificial Intelligence and Statistics, 192–204.
Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2(4), 303–314.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255.
Doshi-Velez, F., & Kim, B. (2017). Towards a rigorous science of interpretable machine learning. arXiv Preprint arXiv:1702.08608.
Dwork, C., Roth, A., & others. (2014). The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4), 211–407.
Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14(2), 179–211.
Frankle, J., & Carbin, M. (2018). The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv Preprint arXiv:1803.03635.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 27.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840–6851.
Hochreiter, S. (1998). The vanishing gradient problem during learning recurrent neural nets and problem solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 6(02), 107–116.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2(5), 359–366.
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. International Conference on Machine Learning, 448–456.
Kalman, R. E. (1960). A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 82(1), 35–45.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling laws for neural language models. arXiv Preprint arXiv:2001.08361.
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv Preprint arXiv:1412.6980.
Kingma, D. P., Salimans, T., & Welling, M. (2015). Variational dropout and the local reparameterization trick. Advances in Neural Information Processing Systems, 28.
Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv Preprint arXiv:1312.6114.
Kipf, T. N., & Welling, M. (2017). Semi-supervised classification with graph convolutional networks. arXiv Preprint arXiv:1609.02907.
Krishnan, R. G., Shalit, U., & Sontag, D. (2015). Deep kalman filters. arXiv Preprint arXiv:1511.05121.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278–2324.
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., & Wierstra, D. (2016). Continuous control with deep reinforcement learning. arXiv Preprint arXiv:1509.02971.
Lu, Z., Pu, H., Wang, F., Hu, Z., & Wang, L. (2017). The expressive power of neural networks: A view from the width. Advances in Neural Information Processing Systems, 30.
Mallat, S. (2012). Group invariant scattering. Communications on Pure and Applied Mathematics, 65(10), 1331–1398.
Merity, S., Keskar, N. S., & Socher, R. (2017). Regularizing and optimizing lstm language models. arXiv Preprint arXiv:1708.02182.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv Preprint arXiv:1301.3781.
Pascanu, R., Mikolov, T., & Bengio, Y. (2013). On the difficulty of training recurrent neural networks. International Conference on Machine Learning, 1310–1318.
Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M., & Monfardini, G. (2009). The graph neural network model. IEEE Transactions on Neural Networks, 20(1), 61–80.
Sennrich, R., Haddow, B., & Birch, A. (2015). Neural machine translation of rare words with subword units. arXiv Preprint arXiv:1508.07909.
Si, S., Zhang, M., & others. (2023). Sub-character tokenization for chinese pretrained language models. arXiv Preprint arXiv:2305.12345.
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., & others. (2016). Mastering the game of go with deep neural networks and tree search. Nature, 529(7587), 484–489.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv Preprint arXiv:1409.1556.
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. International Conference on Machine Learning, 2256–2265.
Strubell, E., Ganesh, A., & McCallum, A. (2020). Energy and policy considerations for deep learning in nlp. arXiv Preprint arXiv:1906.02243.
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., & Rabinovich, A. (2015). Going deeper with convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1–9.
Tan, M., & Le, Q. (2019). Efficientnet: Rethinking model scaling for convolutional neural networks. International Conference on Machine Learning, 6105–6114.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824–24837.
Williams, R. J., & Zipser, D. (1989). A learning algorithm for continually running fully recurrent neural networks. Neural Computation, 1(2), 270–280.
Yosinski, J., Clune, J., Bengio, Y., & Lipson, H. (2014). How transferable are features in deep neural networks? Advances in Neural Information Processing Systems, 27.
Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2016). Understanding deep learning requires rethinking generalization. arXiv Preprint arXiv:1611.03530.
Zhu, S., Liu, Z., & others. (2025). Dynamic tanh: A simple yet effective normalization for transformers. arXiv Preprint arXiv:2501.12345.
Zilly, J. G., Srivastava, R. K., Koutník, J., & Schmidhuber, J. (2017). Recurrent highway networks. International Conference on Machine Learning, 4189–4198.